自动驾驶行业无疑是人工智能技术带来革命性创新的行业之一,自动驾驶技术也随着人工智能技术从深度学习(Deep Learning)到最新的多模态大模型(Multi-modal Large Language Models)的突破,正进入以BEV(Bird’s Eye-View,鸟瞰图)和Transformer为核心的新一代技术框架,为自动驾驶感知能力和泛化能力带来飞跃式的提升。
然而,要训练出能用的BEV模型,我们需要进行大量的数据采集和预处理,这对于场景感知的性能和效果有着至关重要的影响。
而在海量数据的前提下,如何保障数据标注的质量呢?这是我们需要深入探讨的问题。本文将从自动驾驶算法的发展,到BEV+Transformer的优势,再到数据标注的重要性和挑战,以及解决方案等方面进行详细的分析。
1. BEV+Transformer,提升自动驾驶感知能力和泛化能力
自动驾驶算法模块可分为感知、决策和规划控制三个环节,其中感知模块为关键的组成部分,经历了多样化的模型迭代: CNN(2011-2016)—— RNN+GAN(2016-2018)—— BEV(2018-2020)—— Transformer+BEV(2020至 今)—— 占用网络(2022至今)。
目前,在国内BEV+Transformer成为了主流模式。重感知轻地图的自动驾驶解决方案,开启了自动驾驶行业新的篇章。
其背后的关键在于 “第一原则”,即智能驾驶应该越来越接近 “像人一样驾驶”,而映射到感知模型本身,BEV本身就是一种更自然的表达方式。
BEV的优势体现在以下两个方面。
首先,自动驾驶是一个 3D 或 BEV 感知问题。使用 BEV 视角可以提供更全面的场景信息,帮助车辆感知周围环境并做出准确决策。
另一个重要原因是促进多模态融合。自动驾驶系统通常使用多种传感器,如摄像头、激光雷达、毫米波雷达等。BEV视角可以将不同传感器的数据统一表达在同一平面上,这使得传感器数据的融合和处理更加方便。
Transformer大模型,本质上是基于自注意力机制的深度学习模型,由于全局注意力机制,Transformer更适合进行视图转换。目标域中的每个位置访问源域中任何位置的距离都是相同的,克服了CNN 中卷积层感受野的局部局限性。
两者结合可以充分利用BEV提供的环境空间信息,以及 Transformer在多源异构数据建模方面的能力,实现更精确的环境感知、更长远的运动规划和更全局化的决策。
Tesla成为这一技术方向的引领者,随着Tesla快速验证和发布其最新的FSD产品 特斯拉的算法日益成熟,在处理无车道线的崎岖山路、无保护左转、闹市区人流密集区域行驶、夜间闹市行驶、恶劣天气下行驶等场景时表现令人印象深刻。
目前FSD Beta版本尚未在国内开放,根据36氪消息,特斯拉已在中国建立数据中心,并布局组建国内运营团队和 数据标注团队。
诸多国内自动驾驶企业陆续跟进BEV+Transformer的算法研发以及整体数据闭环体系的搭建,并推出各自的城市自动驾驶功能。
在大模型催化下,高速NOA、通勤NOA、城市NOA 等功能快速上车,同时有望加快L3及以上自动驾驶落地进程。

2. 海量数据的前提下,如何保障数据标注的质量?
尽管BEV+Transformer已经成为自动驾驶算法主流趋势。但前提是训练出能用的 BEV 模型。而训练能用BEV,需要进行大量的数据采集和预处理,这对场景感知的性能和效果有着重要影响。
根据特斯拉 2022 年公布的信息,使用 BEV + Transformer 的特斯拉 FSD 模型有 10 亿个参数,大概是上一版模型的 10 倍。
“训练数据越多,结果就越好,” 特斯拉 CEO 埃隆·马斯克(Elon Musk)在 7 月财报会上再次谈到数据对自动驾驶系统的影响,“只用一百万个训练样本时,它(模型)几乎无法工作;两百万个,它才稍微有些效果;三百万个时,我们会惊叹,好像看到了一些东西。到了一千万个时,它就变得令人难以置信。”
只有数据不够。训练 BEV 模型还是一个庞大的体系工程,关键步骤之一是标注好数据。数据标注质量直接决定了模型质量。
此外,由于中国道路的复杂性,天气情况的多变性等因素,对中国的自动驾驶行业来说,面对如此庞大且多元的标注对象,保障数据标注的高质量,并能在较短时间内完成高质量的标注。也成为了车企们亟待解决的难题。
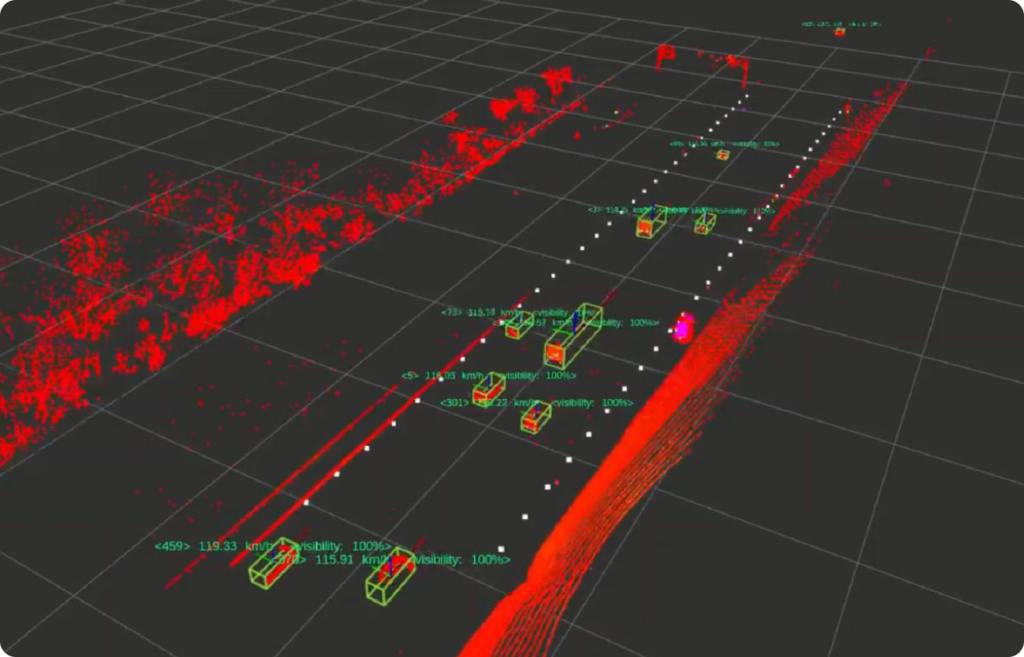
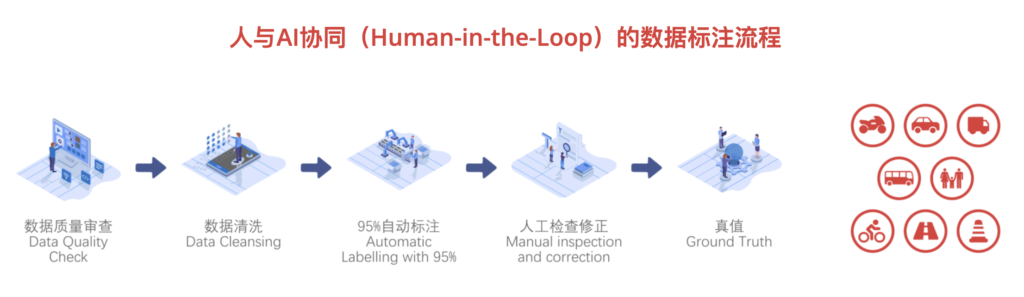
为了更好的帮助中国自动驾驶行业解决这一难题,历经多年的研发和测试,马达智数自有MaidX Auto-4D 平台强势上线。它是一个 “Human-in-the-loop“的自动标注平台,支持 BEV 多传感器融合数据。
马达智数根据在自动驾驶领域的多年的经验,发现该可以将人工标注成本大幅降低 90% 或更多。
举例来说,如果是纯人工的数据生产,一小时的数据需要3000~5000个人工小时。儿使用MaidX Auto-4D,一小时的数据可以缩减至200~500个人工小时。

MaidX Auto-4D的“人与AI协同(Human in the Loop)”自动标注流程包括:数据质量审查,数据清洗,95% 自动标注,人工检查修正,真值。
MaidX Auto-4D 平台,优势如下:
1. 支持BEV多传感器融合数据的自动标注引擎;
2. 支持 BEV 下的多传感器融合数据标注;
3. 全方位目标对象属性(ID、维度、位置、分类、速度、加速度、遮挡关系、可见度、轨迹、所属车道等);
4. 采用前向/后向跟踪,利用历史和未来信息提高当前帧的检测精度;
5. 支持多任务的深度学习模型(分割、物体检测等);
6. 可降低90%以上的人工标注成本;
想客户所想,马达智数自有MaidX Auto-4D 平台,一站式解决对海量且多元数据的高效且高质量标注需求。 保障质量的同时,更是近一步缩短标注时间,减少标注成本,并提高3~4倍的标注效率。
更多详情,请访问:https://madacode.com/autonomous-driving/