
生成式AI大规模语言模型对数据提出了全新的要求,马达智数基于在数据处理与标注领域的多年技术积累,正式推出了面向以ChatGPT为代表的预训练大语言模型的全流程的专业化数据服务。
随着视频应用的发展,海量视频被上传到互联网上。因此,如何利用视频和相应的弱化字幕来进行表征学习,最近成为一个热门话题。
视觉语言任务侧重于图像和文本模式,如基于语言的图像检索和图像说明,而视频语言任务则强调视频和文本模式,在成像模式中加入时间成分。
预训练数据集的规模和质量在学习稳健的视觉表征方面起着重要作用。另外,基于变换器的模型比对应的卷积网络需要更大规模的训练数据。一些有代表性的数据集出现,比如Howto100M和Kinetics,促进了视频语言的预训练。
由马达智数整理,接下里将详细介绍这些数据集,并简单地将这些数据集分为两类,即基于标签的数据集和基于标题的数据集。
一、基于标签的视频数据集
1. Kinetics dataset
kinetics数据集是一个具有多样化类别的大规模动作识别数据集。
Kinetics收集了多达65万个视频片段的大规模、高质量的URL链接,涵盖了400/600/700个人类动作类别。这些视频包括人与物的互动,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
每个动作类别至少有400/600/700个视频片段。而根据动作类别和视频数量,可以将动力学分为三个数据集。Kinetics400,Kinetics600,和Kinetics700。
每个片段都有一个动作类别的注释,持续时间约为10秒。下图可以看到Kinetics的例子。Kinetics涵盖了现实世界中的各种场景和动作。由于视频数量众多,Kinetics经常被用来对视频模型进行逐一训练。

链接:https://www.deepmind.com/open-source/kinetics
2. AVA Dataset
AVA数据集在15分钟的电影片段中密集地标注了80个原子视觉动作,这些动作在空间和时间上都被定位,产生了162万个动作标签,每个人的多个标签经常出现。这个数据集的主要特点是:
(1)原子视觉动作的定义,而不是复合动作;
(2)精确的空间-时间注释,每个人可能有多个注释;
(3)在15分钟的视频片段中对这些原子动作进行详尽的注释;
(4)人们在连续的片段中的时间联系;
(5)使用电影来收集不同的动作表示。
下图说明了AVA数据集的例子。注释是以人为中心的,采样频率为1赫兹。每个人都是用一个边界框来定位的,所附的标签对应于演员正在进行的(可能是多个)动作。
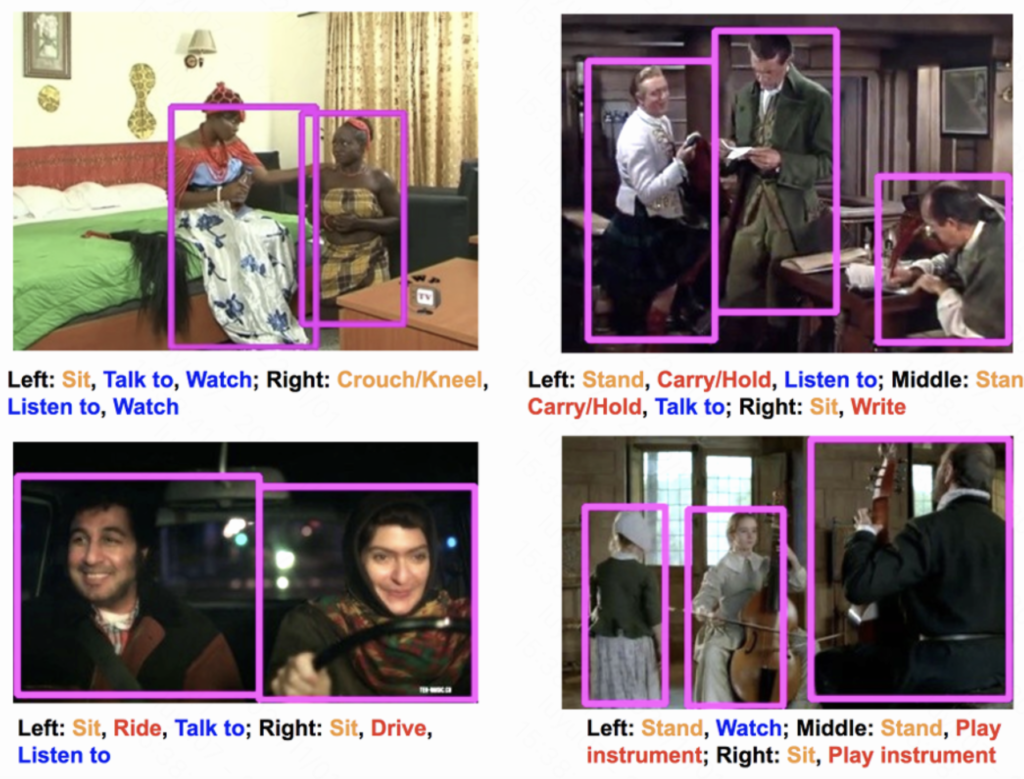
链接: https://research.google.com/ava/
二、基于字幕的视频数据集
ActivityNet Captions包含20k个视频,共计849个视频小时,共有100k个描述,每个描述都有其独特的开始和结束时间。每个句子的平均长度为13.48个单词,也呈正态分布。这些数据经常被用于视频-文本检索或视频-时刻检索任务。
下图显示了ActivityNet字幕数据集的一个例子,这个视频被分为五个片段,每个片段都有一个描述性的句子。
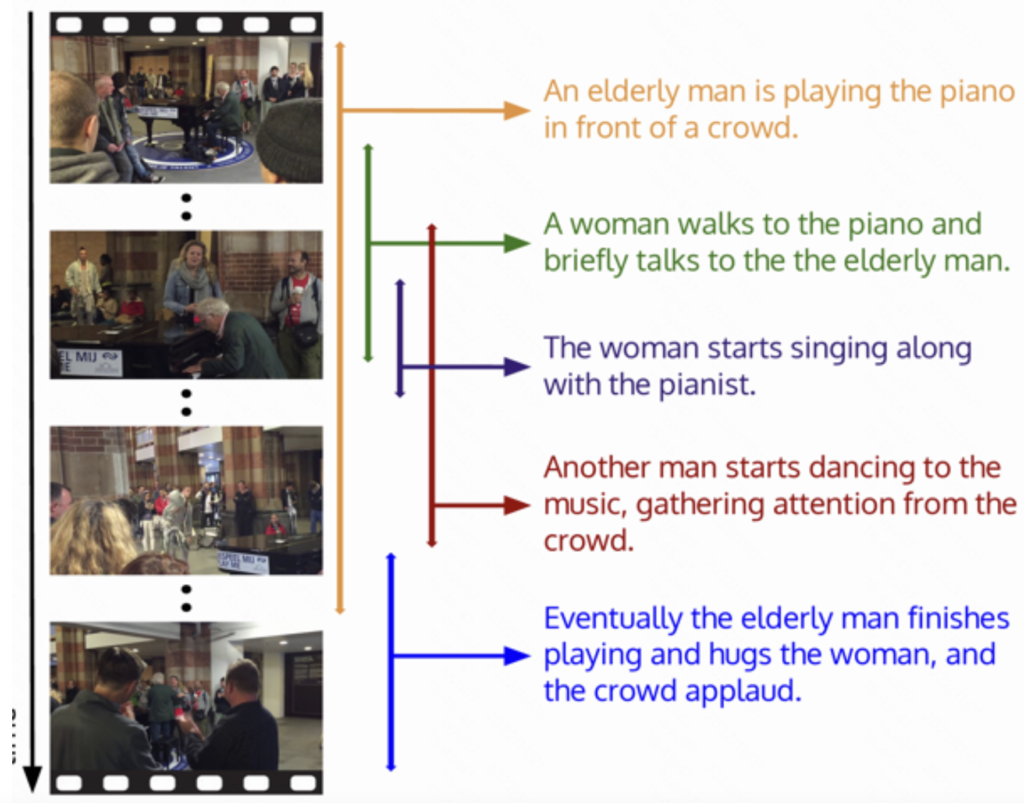
链接: https://paperswithcode.com/dataset/activitynet-captions
4. YouCook2
YouCook2是视觉界最大的面向任务的教学视频数据集之一。它包括89个烹饪食谱中的2000个冗长的、未经剪辑的视频,每个食谱平均有22个视频。每个视频的程序阶段都标有时间界线,并以工具性的英语陈述。
这些视频来自YouTube,都是以第三人称视角为特征。所有的视频都是不受限制的,任何人都可以在自己家里用不固定的摄像机制作。YouCook2提供了来自世界各地的各种食谱类型和烹饪方法。
视频总时间为176小时,每个视频的平均长度为5.26分钟。捕获的每段视频都在10分钟之内,由摄像设备记录。
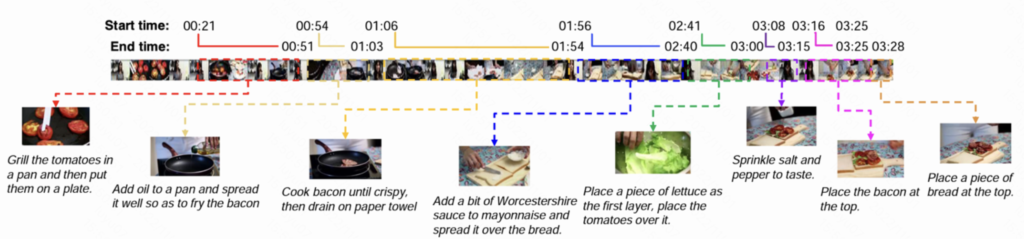
链接:http://youcook2.eecs.umich.edu/
5. Howto100m
HowTo100M是一个大规模的叙事视频数据集,重点是教学视频,其中内容创作者教授复杂的任务,并明确表示要对屏幕上的视觉内容进行解释。
这个数据集包含了超过1.36亿的视频片段,这些视频片段的字幕来自于120万个Youtube视频。其中有2.3万个活动,来自烹饪、手工制作、个人护理、园艺或健身等领域。对于大规模的数据集,Howto100m成为视频语言预训练方法的黄金标准数据集.

链接:https://www.di.ens.fr/willow/research/howto100m/
6. WebVid
WebVid数据集有两个分割版本[10],即WebVid-2M和WebVid-10M。最流行的版本是WebVid-2M,它包括超过200万个从互联网上搜刮来的带有弱化字幕的视频。
Web2vid数据集由人工生成的标题组成,这些标题大部分都是形成良好的句子。相比之下,HowTo100M是由连续的叙述产生的,其中有不完整的句子,缺乏标点符号。因此,WebVid数据集更适合于视频语言的预训练任务,以学习开放领域的跨模式表征。如图15所示,WebVid数据集包含手动注释的标题。

链接:https://m-bain.github.io/webvid-dataset/
7. HD-VILA
高分辨率和多样化的视频语言预训练模型(HD-VILA)数据集是最近推出的一个用于视频语言预训练的大规模数据集。该数据集是:
(1)第一个高分辨率数据集,由330万个视频中的1亿个视频片段和句子对组成,包括371.5K小时的720p视频;
(2)最多样化的数据集,涵盖15个流行的YouTube分类。

链接:https://github.com/microsoft/XPretrain/tree/main/hd-vila-100m
————————————————————————————————————————————————————————————








